We dive into SuperPoint Transformer, a novel approach for 3D semantic segmentation presented in the research paper “Efficient 3D Semantic Segmentation with Superpoint Transformer“. We also explore the core concepts, examine the research methodology, and unpack the key takeaways from the paper, with one of its author.
1. Introduction to SuperPoint Transformer
SuperPoint Transformers proposes a new framework for 3D semantic segmentation tasks. It leverages transformers, a deep learning architecture that has revolutionized natural language processing and incorporates superpoints—segment-level descriptors extracted from 3D point clouds. This integration aims to achieve efficient and accurate 3D semantic segmentation.
And who better to teach us how to leverage this approach than Damien Robert, the paper’s main author?
2. Superpoint Transformer: The Related Resources 🍇
- Original Paper: Efficient 3D Semantic Segmentation with Superpoint Transformer – The foundational research paper detailing SuperPoint Transformers.
- Project Page: (SPT ICCV2023) – Transformer-based models x Superpoint-based models.
- GitHub Repository: (SPT Github) – The codebase for implementing SuperPoint Transformers available on GitHub.
- Tutorial Materials:
- State-of-the-Art Articles:
If you want to explore related research, you can check out my Connected Papers Graph to help you.
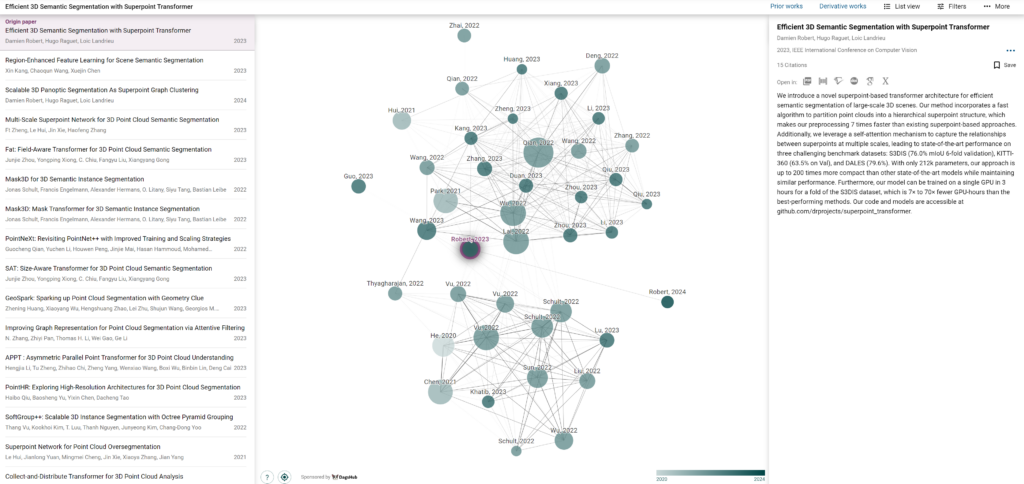
3. The Workflow
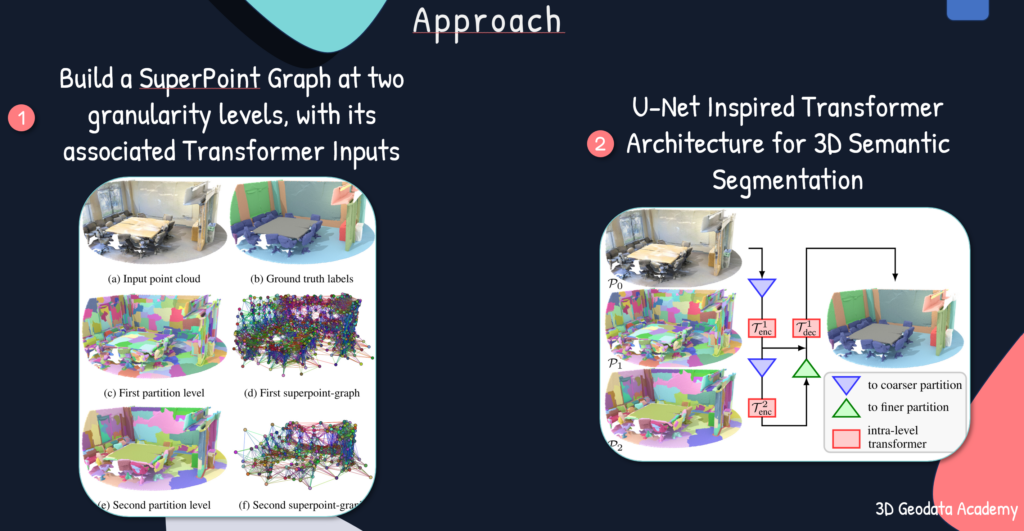
The SuperPoint Transformers workflow can be summarized as follows:
- Superpoint Extraction: The approach begins by extracting superpoints, informative segment-level descriptors, from the input 3D point cloud.
- Transformer Encoding: These superpoints are then fed into a transformer encoder, where they learn contextual relationships and high-level features.
- Segmentation Prediction: Finally, a decoder network leverages the encoded features to predict the semantic segmentation labels for each point in the cloud.
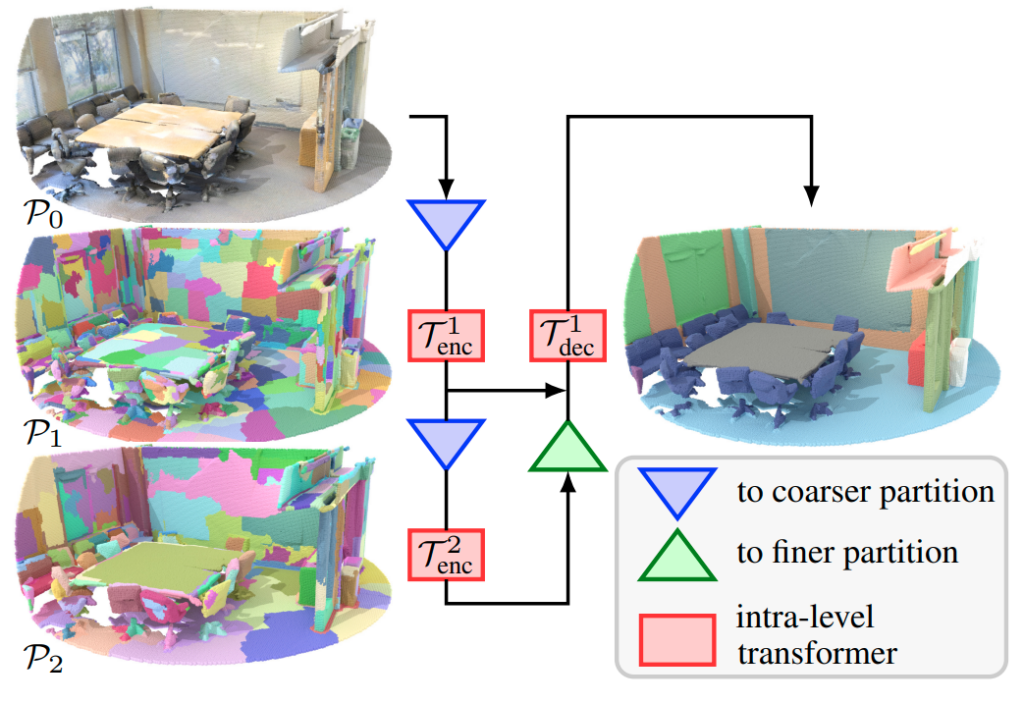
4. The SuperPoint Transformer Results (Key Learning Points)
The research evaluates SuperPoint Transformers on standard 3D segmentation benchmarks. The results demonstrate that the proposed method achieves competitive accuracy while maintaining efficiency compared to existing techniques. Here are some key takeaways:
- SuperPoint Transformers effectively integrates transformers into the 3D segmentation domain.
- The approach offers promising results in terms of accuracy and efficiency.
- This research paves the way for further exploration of transformer-based architectures for 3D data processing tasks.

5. The Next Steps
SuperPoint Transformers offer a promising direction for efficient and accurate 3D semantic segmentation. Future research might involve:
- Exploring various transformer architectures for 3D data.
- Investigating the application of SuperPoint Transformers to different 3D tasks like object detection and scene parsing.
- Delving deeper into the interpretability of the learned features within the transformer.
By continuing research efforts, SuperPoint Transformers have the potential to improve the capabilities of 3D computer vision systems significantly.
Other 3D Tutorials
- 3D Point Cloud Labeling from Photos with Python (and why AI can’t design it for you)
- 3D Pipeline Architecture: A Founder’s Blueprint
- Multi-View Engine for 3D Generative AI Models (Python Tutorial)
- 3D Scene Graphs for Spatial AI with NetworkX and OpenUSD
- 3D Reconstruction Pipeline: Photo to Model Workflow Guide
- Synthetic Point Cloud Generation of Rooms: Complete 3D Python Tutorial
- 3D Generative AI: 11 Tools (Cloud) for 3D Model Generation
- 3D Gaussian Splatting: Hands-on Course for Beginners
- Building a 3D Object Recognition Algorithm: A Step-by-Step Guide
- 3D Sensors Guide: Active vs. Passive Capture
- 3D Mesh from Point Cloud: Python with Marching Cubes Tutorial
- How To Generate GIFs from 3D Data with Python
- 3D Reconstruction from a Single Image: Tutorial
- 3D Reconstruction Methods, Hardware and Tools for 3D Data Processing
- 3D Deep Learning Essentials: Ressources, Roadmaps and Systems
If you want to get a tad more toward application-first or depth-first approaches, I curated several learning tracks and courses on this website to help you along your journey. Feel free to follow the ones that best suit your needs, and do not hesitate to reach out directly to me if you have any questions or if I can advise you on your current challenges!
Open-Access Knowledge
- Medium Tutorials and Articles: Standalone Guides and Tutorials on 3D Data Processing (5′ to 45′)
- Research Papers and Articles: Research Papers published as part of my public R&D work.
- Email Course: Access a 7-day E-Mail Course to Start your 3D Journey
- Youtube Education: Not articles, not research papers, open videos to learn everything around 3D.
3D Online Courses
- 3D Python Crash Course (Complete Standalone). 3D Coding with Python.
- 3D Reconstruction Course (Complete Standalone): Open-Source 3D Reconstruction (incl. NERF and Gaussian Splatting).
- 3D Point Cloud Course (Complete Standalone): Pragmatic, Complete, and Commercial Point Cloud Workflows.
- 3D Object Detection Course (3D Python Recommended): Practical 3D Object Detection with 3D Python.
- 3D Deep Learning Course (3D Python Recommended): Most-Advanced Course for Top AI Engineers and Researchers
3D Learning Tracks
- 3D Segmentator OS: 3D Python Operating System to Create Low-Dependency 3D Segmentation Apps
- 3D Collector’s Pack: Complete Course Track from 3D Data Acquisition to Automated System Creation