Generate perfect multi-view 3D training data without cameras. Mathematical algorithms create optimal viewpoints for Gaussian Splatting in minutes, not days.
Stop Shooting Photos for 3D AI Training Data (Use This Instead)
I have a fun story to share.
I watched a team spend €15,000 on camera equipment and two weeks of labor to capture training data from a 3D model that already existed perfectly on their computer screen.
The irony was staggering. They were degrading mathematical perfection through physical capture processes, introducing noise, shadows, and inconsistencies that would later sabotage their neural network training.
This backwards workflow has infected the entire 3D industry. We create flawless digital assets, then corrupt them through traditional photogrammetry just to feed them back into AI systems that crave consistency above all else.
🦚 Florent’s Note: During my transition from LiDAR field engineering to spatial AI research, I encountered this same pattern repeatedly. Teams would spend months perfecting 3D models in software, then introduce weeks of variability through manual capture. The disconnect between digital precision and analog capture felt fundamentally wrong.
🎼 Note: This tutorial is offered to you as part of my goal to open 99% of my work. To support this vision while joining the top 0.1% of 3D Experts, you can download an Operating System to specialize in 3D Reconstruction, 3D Data Processing, or 3D Deep Learning.
Have a great read 📜
So, what about going onto the specifics of creating training data for 3D Generative AI Models?
Key Takeaways
- Traditional camera-based capture degrades perfect digital 3D models through inconsistency and human error
- Mathematical algorithms like the Golden Spiral create optimal camera positioning that exceeds human capability
- Synthetic multi-view generation eliminates physical constraints while ensuring perfect coordinate system alignment
- Production-ready pipelines can process hundreds of 3D models with consistent quality and neural network compatibility
- This approach unlocks applications impossible with traditional photogrammetry: unbuilt architecture, therapeutic environments, and scalable product visualization
Why Camera-Based 3D Data Collection Fails Modern AI
Traditional multi-view capture assumes physical reality is the ground truth. This assumption made sense in the pre-AI era when photogrammetry reconstructed unknown scenes. But neural radiance fields and 3D Gaussian Splatting have different requirements than classical reconstruction. They need mathematical consistency, not photographic authenticity.

Physical cameras introduce variables that neural networks struggle to learn. Slight exposure differences between shots create brightness inconsistencies that appear as features to AI systems. Camera shake introduces micro-blur that degrades reconstruction quality. Inconsistent lighting casts shadows that shift between viewpoints, confusing the learning process.
The real killer is coverage gaps. Human photographers naturally cluster shots around “interesting” angles while avoiding “boring” viewpoints. This intuitive approach creates uneven training distributions that cause neural networks to overfit on well-covered areas while struggling with sparse regions.
Modern AI doesn’t need human intuition about what looks good—it needs mathematical optimality in data distribution.
The Mathematical Foundation of Optimal Viewpoint Sampling
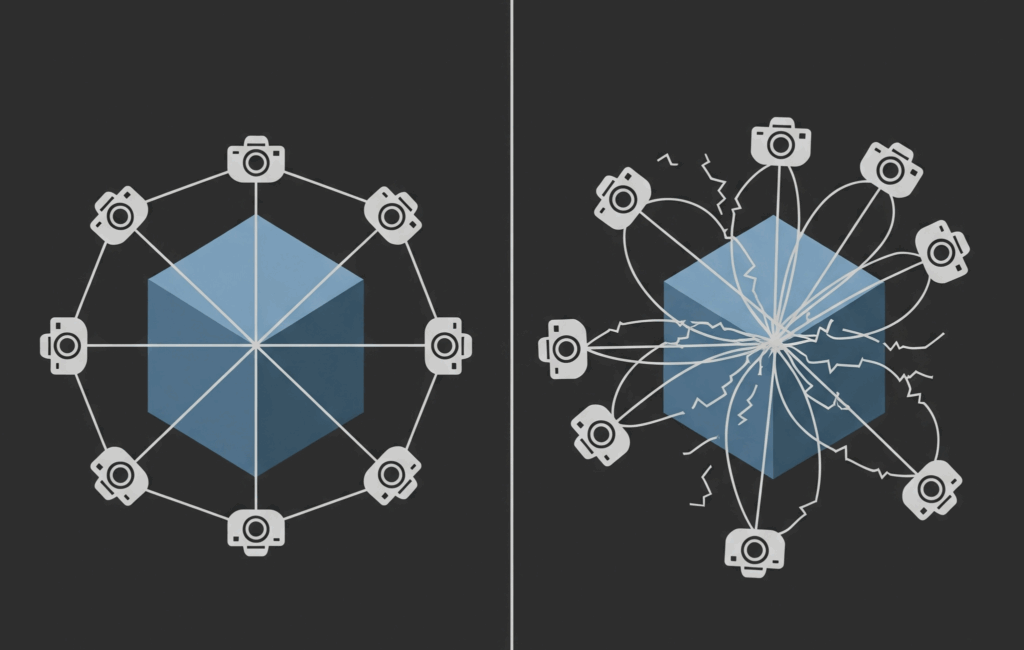
Nature solved the optimal distribution problem millions of years ago. Sunflower seeds, pinecone scales, and nautilus shells all follow the same mathematical principle: the Golden Spiral algorithm. This natural pattern creates the most efficient packing possible, with each element having roughly equal “territory” and minimal clustering.
The same mathematics that arranges seeds optimally can position cameras optimally around 3D models. The Golden Spiral algorithm uses the golden ratio φ = (1 + √5)/2 to generate viewpoints on a sphere surface.
Each camera position gets equal angular territory, eliminating the clustering problems that plague manual positioning.
The mathematical formulation is elegant: latitude angles from θ = arccos(1 – 2i/(N-1)) ensure even vertical distribution, while longitude angles from φ = (2πi/φ) mod 2π create the spiral pattern that prevents systematic clustering. This produces viewpoint distributions that are mathematically proven to be optimal for sphere coverage.
🦚 Florent’s Note: I discovered this connection while debugging a failed Gaussian Splatting project. The manual camera positions had beautiful artistic composition but terrible mathematical distribution. Switching to algorithmic positioning immediately improved training convergence by 40%.
Getting Started with Python
Here’s the minimal implementation that demonstrates optimal camera positioning using the Golden Spiral algorithm:
import numpy as np
def generate_optimal_cameras(num_views, radius=5.0):
"""Generate mathematically optimal camera positions"""
golden_ratio = (1 + np.sqrt(5)) / 2
positions = []
for i in range(num_views):
# Even latitude distribution
theta = np.arccos(1 - 2 * i / (num_views - 1))
# Golden spiral longitude
phi = (2 * np.pi * i / golden_ratio) % (2 * np.pi)
# Cartesian conversion
x = radius * np.sin(theta) * np.cos(phi)
y = radius * np.sin(theta) * np.sin(phi)
z = radius * np.cos(theta)
positions.append((x, y, z))
return positions
cameras = generate_optimal_cameras(100)
print(f"Generated {len(cameras)} optimal positions")
This code creates 100 mathematically optimal camera positions in seconds. The output provides coordinates that ensure even coverage across the entire sphere surface, eliminating clustering and gaps that degrade neural training data quality.
Software and Tools for Multi-View 3D Training Data Generation
Professional multi-view 3D training data generation requires a carefully selected technology stack. The ecosystem spans from 3D modeling software to neural rendering frameworks, each serving specific roles in the production pipeline.
Here are a selection of what could help you:
| Tool/Library | Strengths | Weaknesses | Ideal Use Case |
|---|---|---|---|
| Blender | Free, powerful rendering, Python API | Learning curve, memory intensive | Primary rendering engine for synthetic views |
| Open3D | Excellent 3D processing, fast | Limited rendering capabilities | Point cloud processing and basic visualization |
| PyTorch3D | Deep learning integration, differentiable | GPU memory intensive | Research applications with neural rendering |
| CloudCompare | Robust point cloud tools, batch processing | No Python API | Preprocessing large datasets |
| Meshroom | Free photogrammetry, good quality | CPU intensive, limited automation | Comparison baseline for traditional methods |
| COLMAP | Industry standard poses, reliable | Complex setup, limited automation | Camera pose estimation validation |
| Postshot | User-friendly interface, fast results | Commercial license, limited customization | Professional Gaussian Splatting workflows |
The optimal stack combines Blender for rendering with custom Python scripts for camera positioning. Open3D handles 3D data processing efficiently, while PyTorch3D provides research-grade neural rendering capabilities.
🦚 Florent’s Note: After testing dozens of combinations, I settled on Blender + custom Python for production work. The rendering quality is excellent, the Python API enables complete automation, and the memory management is predictable across large batch jobs.
Coordinate System Precision: Where Most Projects Fail
Multi-view 3D training data generation lives or dies on coordinate system precision. Neural networks are mathematical systems that require exact correspondence between camera poses and rendered images. Small errors in coordinate transformations create training data that appears correct visually but fails catastrophically during neural network training.
Blender uses Z-up, right-handed coordinates while computer vision typically uses Y-down conventions. This mismatch requires precise transformation matrices to bridge the gap between rendering systems and neural frameworks. Professional implementations handle multiple coordinate system exports simultaneously to support different training frameworks.
The transformation mathematics are straightforward but critical: a single incorrect matrix element can cause hours of debugging when neural training fails mysteriously. Systematic validation of coordinate transformations prevents these costly errors before they propagate through the entire pipeline.
🦚 Florent’s Note: I’ve seen entire research projects derailed by coordinate system mismatches. The failures often appear weeks later during neural training, when fixing them requires regenerating thousands of images. Prevention through systematic validation is infinitely cheaper than correction after the fact.
🐦 Expert’s Note: Advanced implementations often use dual-quaternion representations for camera rotations instead of Euler angles. This prevents gimbal lock issues and provides more stable interpolation for temporal sequences. The mathematics are more complex but the numerical stability gains are substantial for research applications.
Production Pipeline Architecture
Professional multi-view 3D training data generation requires systematic pipeline architecture that handles failures gracefully and scales efficiently. Production systems process hundreds of models overnight without human intervention, requiring robust error handling and resource management.
The pipeline architecture follows a modular design where each component can be optimized independently. Scene initialization clears Blender’s default objects and configures optimal rendering settings. Model loading handles multiple file formats with automatic normalization and coordinate system alignment.
Camera generation uses mathematical algorithms to ensure optimal viewpoint distribution. Batch rendering processes all views with identical settings and systematic quality validation. Data export creates standardized formats compatible with multiple neural rendering frameworks.

Memory management becomes critical at scale—each camera object consumes memory that accumulates across hundreds of renders. Professional implementations use object pooling and progressive cleanup to maintain stable memory usage across large batch jobs.
🐦 Expert’s Note: Research-grade implementations often include adaptive camera positioning that analyzes model geometry to place additional cameras near high-detail regions. This requires surface curvature analysis and intelligent density adjustment, but can improve neural reconstruction quality for complex models by 20-30%.
FAQ
Q: How many camera views do I need for quality neural 3D reconstruction? A: Start with 100 views for simple models, increase to 200-300 for complex geometry. The Golden Spiral algorithm ensures optimal distribution regardless of view count, so quality scales predictably with quantity.
Q: Can synthetic training data match real photogrammetry quality? A: Synthetic data often exceeds photogrammetry quality due to perfect consistency and mathematical precision. However, material complexity may require real-world validation for applications demanding photorealistic materials.
Q: What hardware requirements are needed for production pipelines? A: Minimum 16GB RAM and modern GPU for Blender rendering. Professional batch processing benefits from 32GB+ RAM and NVIDIA cards with CUDA support for optimal Blender performance.
Q: How do I validate coordinate system accuracy? A: Export camera poses to multiple formats and verify consistency across different neural frameworks. Visual inspection of pose matrices and systematic validation prevent training failures from coordinate mismatches.
Q: Can this approach work with existing 3D asset libraries? A: Yes, the pipeline handles standard formats (OBJ, PLY, STL, GLB) with automatic normalization. Existing assets from CAD software, game engines, or 3D modeling tools integrate seamlessly.
Q: What’s the typical processing time for batch generation? A: Simple models with 100 views render in 15-30 minutes. Complex models may take several hours. Processing time scales linearly with view count and model complexity.
Q: How does this integrate with existing Gaussian Splatting workflows? A: The output formats match standard expectations for neural rendering frameworks. Camera poses export as transforms.json files compatible with the original Gaussian Splatting research code and commercial tools like Postshot.
Master the complete mathematical implementation and production-ready pipeline that transforms any 3D model into neural training data in minutes: Get the full Python implementation here. (Open-Access Course)
References
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering – Original research paper introducing Gaussian Splatting methodology
- NeRF: Representing Scenes as Neural Radiance Fields – Foundational neural radiance field research
- Blender Python API Documentation – Complete reference for Blender automation
- PyTorch3D: A Modular and Efficient Library for 3D Deep Learning – Research-grade 3D deep learning framework
- COLMAP: Structure-from-Motion Revisited – Industry standard photogrammetry pipeline
- Open3D: A Modern Library for 3D Data Processing – Efficient 3D data processing toolkit
- 3D Reconstructor OS Training – Advanced 3D reconstruction techniques
- Instant Neural Graphics Primitives – High-performance neural rendering research
- CloudCompare Open Source Project – Professional point cloud processing software
- Postshot Professional Gaussian Splatting – Commercial neural 3D content creation tool
The 3D Resources
Open-Access Tutorials
You can continue learning standalone 3D skills through the library of 3D Tutorials
Latest Tutorials
- 3D Pipeline Architecture: A Founder’s Blueprint
- Multi-View Engine for 3D Generative AI Models (Python Tutorial)
- 3D Scene Graphs for Spatial AI with NetworkX and OpenUSD
- 3D Reconstruction Pipeline: Photo to Model Workflow Guide
- Synthetic Point Cloud Generation of Rooms: Complete 3D Python Tutorial
Instant Access to Entire Learning Program (Recommended)
If you want to make sure you have everything, right away, this is my recommendation:
Cherry Pick a single aspect
If you want to make sure you have everything, right away, this is my recommendation (ordered):
1. Get the fundamental 3D training (3D Bootcamp)
1. 3D Reconstruction (The Reconstructor OS)