It was a Tuesday when I got the call. A €40,000 project was completely stalled, burning cash every hour. The reason? The one person who knew the specific sequence of clicks to get data from their laser scanner software into AutoCAD was on vacation.
The entire, expensive, high-tech 3D data pipeline was held hostage by a manual “Export/Import” process. This wasn’t a unique disaster; it was a symptom of a systemic failure I see everywhere.
We’ve filled our toolchains with incredible, specialized software, yet our workflows are more fragile than ever. We stitch them together with manual labor and brittle scripts, creating a system that’s guaranteed to fail.
The problem isn’t our tools. It’s the architecture—or lack thereof—that connects them.
So, how do you build a 3D data pipeline that is resilient, scalable, and doesn’t depend on a single person’s muscle memory?
Key Takeaways
- Fragmentation is the Silent Killer: Relying on 5-10 different tools with manual handoffs creates invisible bottlenecks that stall projects and inflate costs.
- Brittle Automation is a Trap: Simple scripts connecting tools often break with software updates, forcing teams back to inefficient manual processes.
- Adopt a Software Engineering Mindset: A three-layer architecture (Ingest, Process, Deploy) separates concerns, making your pipeline modular and robust.
- Standardize Your Core: Convert all incoming data into a single, standardized internal format (like NumPy arrays) to decouple your algorithms from specific file types.
- Configuration Over Code: Define your pipeline’s logic in external configuration files (e.g., JSON), not hard-coded in scripts, to make changes quickly and safely.
The Anatomy of a Broken 3D Data Pipeline
Most 3D data pipelines evolve by accident, not by design.
You start with one tool for data acquisition, add another for cleaning, and a third for modeling. Before you know it, you have a complex chain of dependencies held together by hope and manual labor. This ad-hoc approach creates two primary points of failure: data fragmentation and process bottlenecks.
The fragmentation happens because each tool has its own proprietary or preferred format, leading to constant, risky data conversions. The bottlenecks are the manual handoffs between each step, where human intervention is required to export, check, and import the data.
This is not a scalable system; it’s a ticking time bomb waiting for a deadline or a vacation to go off.
🦚 Florent’s Note: I once spent a week debugging a project where survey results were off by several meters. The error wasn’t in the complex geodetic calculations. It was because someone had manually selected the wrong coordinate system from a dropdown menu during an import step. That single click cost the project thousands and taught me that the most dangerous part of any pipeline is the part that relies on human perfection.
My €40,000 Wake-Up Call: The Manual Handoff Trap
The stalled project was a classic case of the manual handoff trap. The team used a powerful terrestrial laser scanner with its own software, Cyclone, to acquire point clouds. From there, the data had to be moved to RealityCapture for photogrammetric integration, then to AutoCAD and Revit for BIM modeling. Every single arrow in that workflow diagram represented a person manually exporting a file and another person importing it.
This process was slow and prone to error on a good day. But when their key technician went on leave, it ground to a complete halt. No one else was confident they knew the exact export settings or the right import modules to use. The project sat idle, and the client grew impatient, all because the system’s “architecture” was stored in one person’s head.
This is the hidden cost of fragile systems. It’s not just the wasted time; it’s the project risk, the stress on the team, and the inability to grow. You can’t scale a business when your core processes are artisanal, hand-crafted workflows.
Escaping the Automation Illusion of the 3D Data Pipeline
The logical next step for many teams is to try and automate these handoffs. They write a Python script to bridge Tool A and Tool B. It works brilliantly for three months, and then an update to Tool A changes its output format, the script breaks, and since the person who wrote it is now on a different project, everyone just goes back to doing it manually.
This is the automation illusion—mistaking a brittle script for a robust system. I saw a team invest heavily in a script to automate their COLMAP-to-Blender workflow. It was a clever piece of code, but it was hard-coded to expect a very specific data structure.
When a COLMAP update changed that structure, the entire automated pipeline became useless overnight.
🐦 Expert’s Note: For true workflow orchestration, you need to think beyond simple scripts. Tools like Apache Airflow or Prefect allow you to define your pipeline as a Directed Acyclic Graph (DAG). This approach manages dependencies, handles retries, and provides logging and monitoring, turning a fragile script into a managed, observable engineering process.
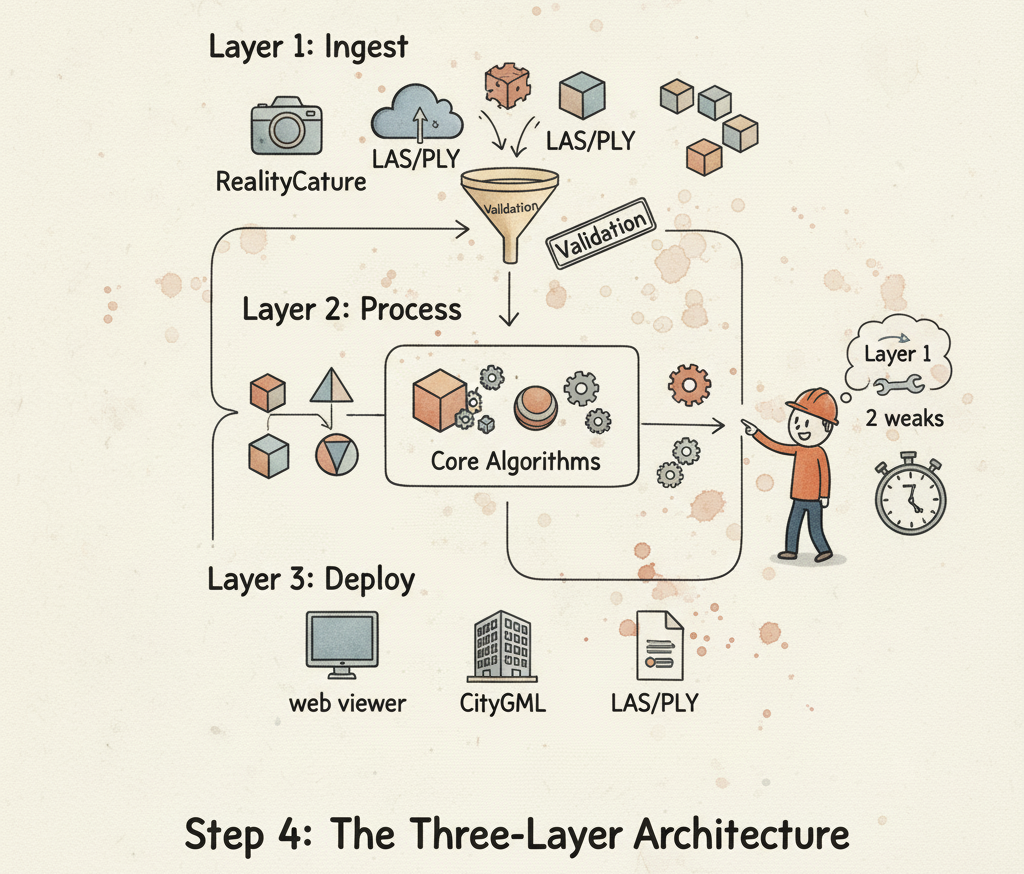
Rethinking the Blueprint: The Three-Layer Architecture
The solution is to stop thinking like a tool operator and start thinking like a software architect. We need to design our pipelines with a clear separation of concerns, creating a system that is modular and resilient to change. I implement this using a simple but powerful three-layer architecture that has saved countless projects.
It consists of an Ingest Layer to handle all incoming data formats, a Process Layer that runs core algorithms on a standardized data type, and a Deploy Layer that outputs the results into any format the client needs.

By isolating these functions, a change in one layer—like a new input source or a required output format—doesn’t break the entire system. This is the blueprint for a scalable and maintainable 3D data pipeline.
🦚 Florent’s Note: The biggest debate when I first designed this was what the “standardized internal format” should be. We settled on structured NumPy arrays. Why? Because it’s the lingua franca of the entire Python data science ecosystem. It’s simple, incredibly fast, and forces you to be explicit about your data structure, which eliminates a huge category of potential bugs.
Getting Started with GeoAI: A Practical 3D Data Pipeline Step
You can begin implementing this architecture today. The first step of any good Ingest layer is validation. Before you do any complex processing, you need to verify that the data you’ve received matches your expectations.
Here is a minimal, copy-and-paste Python function using pandas that checks if a CSV point cloud has the required ‘x’, ‘y’, and ‘z’ columns. This simple check can save you hours of debugging. The output will tell you immediately if the file is valid or if it’s missing the essential columns for 3D processing.
import pandas as pd
def validate_point_cloud_csv(file_path):
"""
Validates a CSV to ensure it contains the necessary point cloud columns.
Args:
file_path (str): The path to the CSV file.
Returns:
bool: True if the file is valid, False otherwise.
"""
try:
df = pd.read_csv(file_path, nrows=1) # Read only the header
required_columns = {'x', 'y', 'z'}
if required_columns.issubset(df.columns):
print(f"Validation successful: '{file_path}' contains required columns.")
return True
else:
print(f"Validation failed: Missing columns {required_columns - set(df.columns)}")
return False
except Exception as e:
print(f"An error occurred: {e}")
return False
# --- Example Usage ---
# Create a dummy valid and invalid file to test
with open("valid_cloud.csv", "w") as f:
f.write("x,y,z,intensity\n1,2,3,99")
with open("invalid_cloud.csv", "w") as f:
f.write("easting,northing,value\n4,5,6")
validate_point_cloud_csv("valid_cloud.csv")
validate_point_cloud_csv("invalid_cloud.csv")Your GeoAI Arsenal: Choosing the Right Tools
Building a robust pipeline means choosing tools that are powerful, flexible, and play well with others. Open-source libraries are often the best choice because they give you maximum control and transparency. Here’s a comparison of key tools for your 3D data pipeline arsenal.
| Tool | Strength | Weakness | Ideal Use Case |
|---|---|---|---|
| PDAL (https://pdal.io/) | Point cloud data abstraction & translation | Steep learning curve for complex pipelines | Ingest Layer: Reading, reprojecting, and writing any point cloud format. |
| Open3D (http://www.open3d.org/) | 3D data structures & processing algorithms | Less mature for large-scale production | Process Layer: Rapid prototyping of 3D algorithms in Python. |
| PyVista (https://docs.pyvista.org/) | Powerful 3D visualization & mesh analysis | Primarily for visualization, not I/O | Deploy Layer: Creating high-quality 3D visualizations and interactive plots. |
| Laspy (https://laspy.readthedocs.io/) | Fast, native reading/writing of LAS/LAZ | Limited to the LAS/LAZ specification | Ingest/Deploy Layer: When your entire workflow is standardized on LAS. |
🐦 Expert’s Note: For truly massive datasets, consider a data versioning tool like DVC (Data Version Control). It works with Git to track your data and models, allowing you to version multi-gigabyte point clouds without bloating your Git repository. This is essential for creating reproducible GeoAI research and production pipelines.
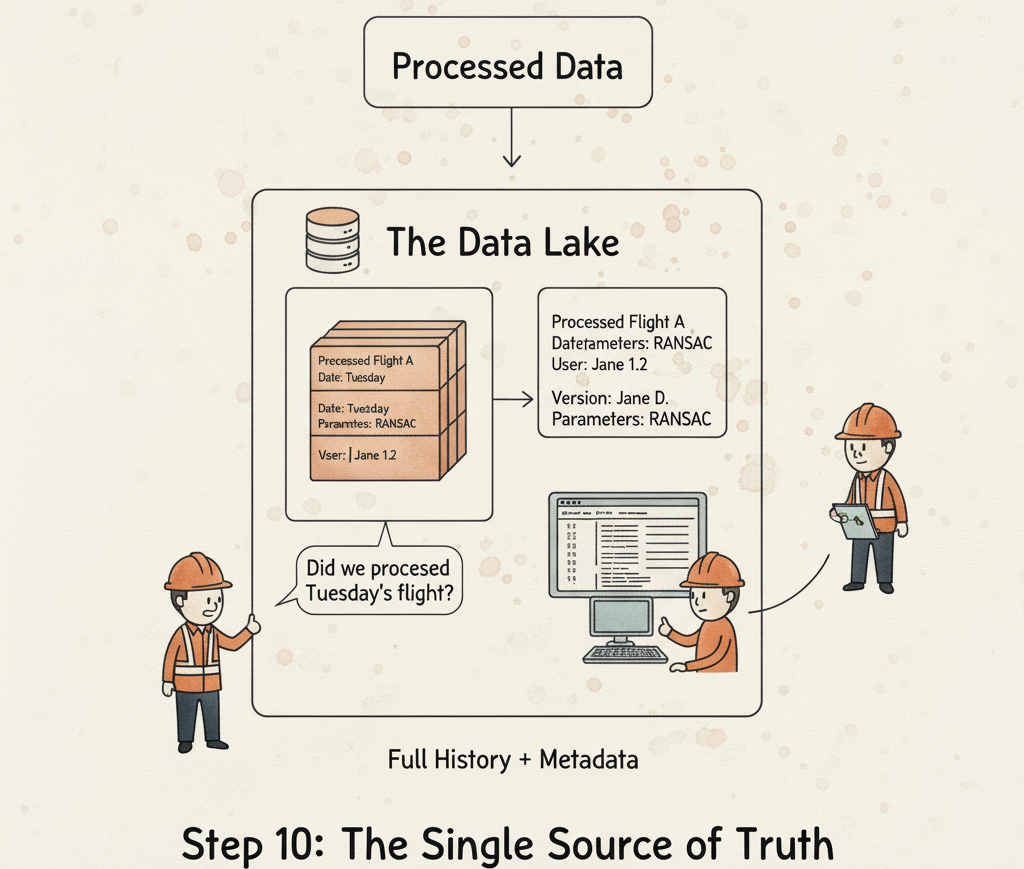
The Autonomous 3D Data Pipeline
This three-layer architecture isn’t just about fixing today’s problems; it’s about preparing for tomorrow’s opportunities. As AI becomes more integrated into our workflows, these robust pipelines will become the backbone of autonomous systems that can ingest, analyze, and deploy 3D data with minimal human oversight. We are moving towards a future where the pipeline itself becomes an intelligent agent.
Market Outlook: The demand for automated 3D data analysis is exploding in sectors like autonomous vehicles, digital twins, and construction verification. Companies that build scalable, reliable data pipelines today will be the ones who can capitalize on this growth. Those who continue with brittle, manual workflows will be left behind, unable to compete on speed, cost, or reliability.
🦚 Florent’s Note: The ultimate goal is to reach a state where you’re not just running a pipeline, but managing a fleet of them. With a solid architecture and configuration-driven design, you can deploy a new, slightly different pipeline for a new client not in weeks, but in minutes. That’s when you’re no longer just processing data; you’re operating a data factory.
Ready to stop fixing broken workflows and start building a truly resilient 3D data pipeline? Dive into the full, step-by-step tutorial and deploy your first robust system this week
FAQ
1. What is the biggest mistake people make when automating 3D pipelines?
The biggest mistake is “tight coupling”—writing a single, monolithic script where every step depends directly on the previous one. A failure in one part, like a file format change, brings down the entire system. A modular, three-layer architecture prevents this.
2. Is this architecture overkill for small projects?
Not at all. The principles scale down perfectly. Even for a one-off project, separating your data loading (Ingest), analysis (Process), and export (Deploy) into different functions will make your code cleaner, easier to debug, and reusable for the next project.
3. What programming language is best for this?
Python is the dominant choice due to its extensive ecosystem of data science (NumPy, Pandas), 3D (Open3D, PDAL), and workflow orchestration (Airflow, Prefect) libraries. It provides the glue to connect all the layers of your architecture effectively.
4. How do I handle massive point cloud files that don’t fit in memory?
This is where the choice of tools becomes critical. Libraries like PDAL are designed to stream data and process it in chunks, so you can handle datasets of any size. Your Process layer should be designed with this in mind, using algorithms that can operate on subsets of the data.
5. Can I integrate proprietary software like Cyclone or RealityCapture into this?
Yes. Your Ingest layer can wrap around the command-line interface (CLI) or SDK of a proprietary tool to extract data into your standard format. Similarly, the Deploy layer can use a CLI to load processed data back into that software for final delivery if a client requires it. The core of your pipeline remains independent and open-source.
References
- PDAL – Point Data Abstraction Library: https://pdal.io/
- Open3D – A Modern Library for 3D Data Processing: http://www.open3d.org/
- The Twelve-Factor App (Methodology for Building Software-as-a-Service): https://12factor.net/
- Prefect – Open-Source Workflow Orchestration: https://www.prefect.io/
- DVC – Data Version Control for Machine Learning: https://dvc.org/
- Structuring a 3D Point Cloud Processing Workflow (Course on learngeodata.eu): https://learngeodata.eu/3d-python-segmentation-course-os/
- Martin Fowler – Patterns of Enterprise Application Architecture: https://martinfowler.com/books/eaa.html